A multimodal foundation model for controllable protein generation and representation learning
PoET-2 is a next generation protein language model that transforms our ability to engineer proteins by learning from nature's design principles. Through its unique multimodal architecture and training paradigm, PoET-2 delivers trillion-parameter performance with just 182 million parameters, significantly outperforming orders-of-magnitude larger foundation models with a fraction of the compute. PoET-2 demonstrates unprecedented insight into the complex interplay between sequence, structure and function, improving the state-of-the-art in diverse protein understanding benchmarks. PoET-2 offers a powerful new grammar and modeling framework for controlling protein design, enabling ML-driven protein engineering with 30-fold less experimental data than existing models. PoET-2 is the next step in realizing the promise of artificial intelligence for decoding and mastering the molecular machinery of life.
The vast array of natural proteins arises from a protein design campaign spanning billions of years. Through countless iterations of mutation and selection, evolution has explored an astronomical space of possible protein sequences, discovering incredible molecular machines that can capture sunlight, break down pollutants, fight disease, and catalyze the chemistry of life. As linear amino acid sequences encoded in genes, these molecules function in the physical world through sequence-dependent physical processes. The complexity of this process and vastness of the sequence design space has limited our ability to understand and engineer these remarkable molecules; there are more possible proteins of just 100 amino acids than there are atoms in the universe. Yet, most of these sequences fail to form useful structures or carry out useful functions.
We present PoET-2, a breakthrough artificial intelligence system that reasons across modalities to understand and design proteins. PoET-2 represents a fundamental departure from existing protein language models (PLMs). By learning simultaneously from evolutionary sequence patterns and protein structure, PoET-2 extracts the fundamental principles that make proteins work. With additional in-context learning capabilities and a sophisticated, programmable design grammar, PoET-2 is able to learn from new data at runtime and solves diverse protein generation problems. This understanding allows it to navigate the vast space of possible proteins with unprecedented precision and efficiency. It also dramatically increases model efficiency. While others have focused on building ever-larger models requiring billions of parameters and massive compute resources, PoET-2 achieves superior performance with just 182 million parameters, delivering orders-of-magnitude faster inference with significantly reduced development and inference costs.
PoET-2 builds on our previous generation model, PoET [1], with three key innovations:
-
A flexible multimodal architecture that seamlessly integrates sequence and structural information, allowing PoET-2 to operate in sequence-only or structure-guided modes, and an encoder-decoder structure that allows sequence generation and state-of-the-art representation learning
-
A powerful context-guided learning system that discovers functional relationships at inference time, allowing PoET-2 to learn from examples without retraining, whether from public or proprietary databases
-
A precise design grammar that enables controlled protein generation while preserving critical functional or structural elements
These architectural advances translate directly into practical capabilities that accelerate protein engineering and unlock new possibilities:
-
Superior generative modeling: PoET-2 achieves protein modeling performance that would require trillion-parameter models using conventional PLM architectures - making it both more powerful and dramatically more efficient.
-
Deep structural understanding: PoET-2 captures structural relationships between distant parts of proteins with unprecedented accuracy, achieving over 80% precision in contact prediction on CASP15, improving more than 10 percentage points over other models.
-
State-of-the-art mutation effect prediction: PoET-2 excels at predicting how mutations affect protein function, particularly for challenging cases like insertions, deletions, and proteins with few known relatives - map sequence variants, design peptide insertions or protein truncations, or prioritize clinical mutants.
-
Mapping protein function: Most importantly for real-world applications, PoET-2 achieves state-of-the-art protein function prediction with orders-of-magnitude less data than existing methods - reducing experimental data needed for protein optimization by up to 30-fold, shortening iteration cycles and reducing costs to reach superior performance.
In this post, we'll walk through the key innovations behind PoET-2's breakthrough capabilities. We'll start by introducing PoET-2 and its control grammar in more detail, illustrating the array of design tasks it can accomplish. Then, we'll show how PoET-2's unique architecture allows it to learn fundamental principles of protein structure and function, breaking scaling laws and achieving state-of-the-art performance on protein sequence generation and structural contact prediction. We'll explore how this deep understanding enables accurate prediction of mutation effects in a zero-shot setting and efficient transfer learning for protein function prediction with minimal experimental data. Finally, we'll demonstrate some of PoET-2's applications, from antibody optimization to enzyme engineering. Throughout, we'll contrast PoET-2 with contemporary protein language models, demonstrating superior accuracy over models like ESM and ProGen.
PoET-2 is available today through the OpenProtein.AI platform, allowing researchers and companies to immediately apply these capabilities to their protein engineering challenges.
PoET-2 Synthesizes Evolutionary and Physical Principles of Proteins with a Unique Architecture
While most protein language models focus on single protein sequences, either masked or autoregressively, or focus on generating sequence from a structure template (inverse folding), natural proteins arise through mutation and natural selection acting on sequence, structure, and function. PoET-2's design mirrors this multifaceted relationship through a multimodal architecture that learns directly from evolutionary-scale sequence and structure data.
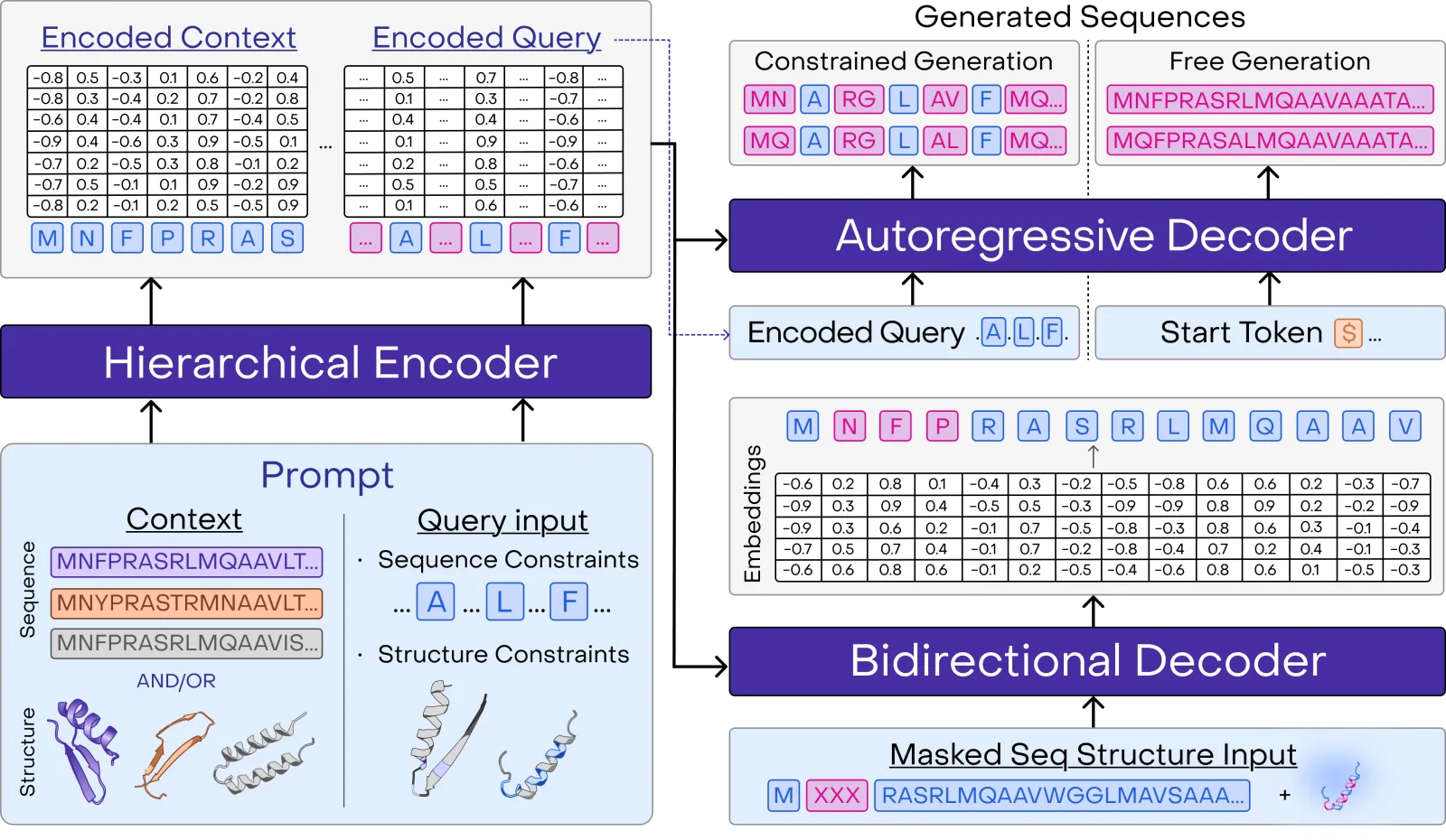
Building on our PoET architecture, the heart of PoET-2 is a bidirectional encoder with our hierarchical attention mechanism that enables powerful in-context learning and generalization across the protein universe (Figure 1). This system processes information at two levels simultaneously; it analyzes relationships between different protein sequences in an order-independent way, while also attending to the ordered relationships between amino acids within each sequence. Unlike our previous generation model, PoET, this encoding is truly sequence-order-equivariant. In addition, when structural information is available, these within-sequence relationships are further enriched by structural context, allowing PoET-2 to understand both sequence patterns and 3D arrangements. For generating outputs, PoET-2 has two decoders: one for autoregressive generation and another for bidirectional language modeling, with parameter sharing. In contrast to other protein language models, this dual-level processing allows PoET-2 to learn from examples that represent the protein fitness landscape of interest at inference time, whether they're evolutionary homologs, structurally or functionally similar proteins, or some other semantic grouping. This allows PoET-2 to generalize to small protein families and new databases without retraining.
PoET-2 is trained on large scale natural protein sequence and structure data with a multi-task learning approach. It learns to:
- Generate diverse new protein sequences conditioned on homologous examples
- Complete partially specified sequences based on a sequence and structure query
- Decode missing amino acids in a conventional masked language modeling objective given sequence-only or structure-conditioned inputs
This training regime enables two modes of operation. The autoregressive decoder excels at generating novel proteins and completing partial sequences, while the bidirectional decoder produces context-aware embeddings that capture deep insights about protein structure and function. These embeddings serve as powerful features for downstream tasks like protein property prediction and optimization. Parameter sharing between these decoders improves parameter efficiency and improves learning across tasks.
The result is a model that can work flexibly with whatever information is available - from structure templates to sequence fragments to evolutionary relationships - to achieve state-of-the-art performance across tasks.
A Controllable Grammar for Protein Generation
PoET2 enables unprecedented control via its prompt, which allows protein engineers to specify the desired attributes of novel generated proteins more precisely than ever before. A prompt is composed of two optional parts: 1) the context, and 2) the query. The context is a set of sequences and structures that guides PoET-2's output distribution and enables PoET-2's in-context learning and retrieval-augmented capabilities. Meanwhile, the query encodes specific sequence and structural constraints, such as the protein's size and the presence of any signal peptides or active sites. This flexible grammar allows sequence generation to be controlled implicitly (by providing sequences/structures describing the desired distribution) and explicitly (e.g., for sequence in-filling or motif scaffolding) (Figure 2). Clever prompt engineering via careful selection of the context allows PoET-2 to focus on the evolutionary, structural, or functional constraints of only the subspace of relevant proteins.
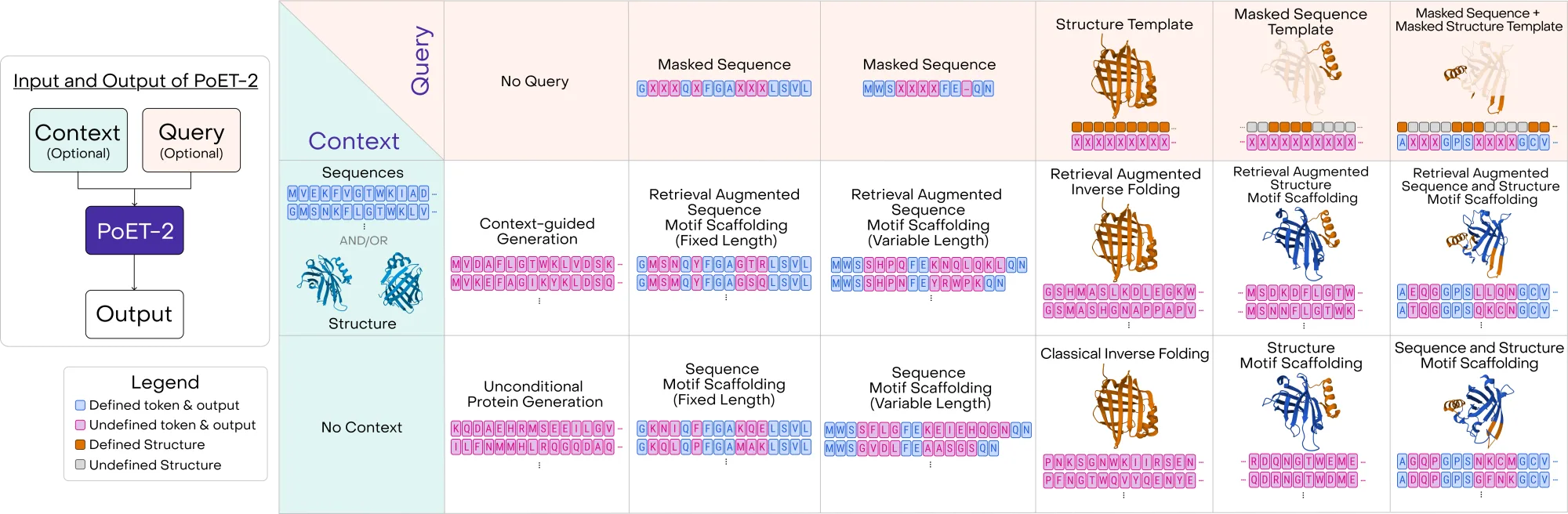
Understanding the PoET-2 Prompt Context
The context guides PoET-2's in-context learning and retrieval-augmented generation capabilities. By prompting PoET-2 with specific sets of sequences or sequences and structures, the generative distribution can be tuned towards specific goals. For example:
- Prompt with the sequences of protein family members for a powerful family-specific biological sequence model
- Construct the prompt from homology search from a parent sequence for evolutionarily-focused variant effect predictions
- Build a prompt from thermophilic organisms to design heat-resistant proteins
- Condition on human antibody repertoire sequences to model the distribution over natural human antibodies to humanize antibodies and improve developability
- Use proprietary sequence or structure databases to extract insights at inference time, no retraining required
Guide Protein Design with a Programmable Query
The query controls PoET-2 outputs. It allows users to specify specific amino acids, sequence length, provide a structural template, or partial structure to accomplish specific protein generation tasks. For example, through the query, PoET-2 can perform:
- Free sequence generation from no query
- Sequence in-filling given a masked sequence query, possibly with variable length regions
- Inverse folding with a structure template query
- Motif scaffolding with a masked structure or sequence query
Together, the context and query can be composed to form powerful prompts for diverse protein generation tasks.
Miniaturizing a Luciferase
Luciferases are enzymes that catalyze a light-releasing reaction and are commonly used as reporters for the study of biological processes. This function has evolved independently across fireflies, copepods, and several other oceanic organisms. One of the most widely used luciferases, NanoLuc, is a small beta barrel protein originally found in a deep sea shrimp. This protein has since been engineered for increased stability and brightness. However, even smaller luciferases would be helpful to reduce interference with the biological processes being observed, payload size, and burden on the cell.
Here, we'll show how PoET-2 can be used to tackle this problem. Starting from the structure of NanoLuc, we can see that there is an external domain away from the active site that is not present in other structural homologues. Let's define a prompt to remove this domain and allow PoET-2 to redesign the sequence and infill the missing structure. Interestingly, NanoLuc has no known homologues, so we'll provide PoET-2 with context from structurally-similar fatty acid transporters. But, because none of these proteins have luciferase activity, we'll also constrain the active site residues to match the luciferase to preserve function.
Prompt: Generate truncated NanoLuc-like luciferases:
- Context: structural homologues of NanoLuc - fatty acid transporters with the same fold but <30% sequence identity.
- Query: NanoLuc structural template with extraneous domain removed and a sequence track with only the active site residues preserved.
Output: PoET-2 generates highly differentiated (<40% sequence similarity) proteins that preserve the active site geometry and overall fold of NanoLuc, but removes the external domain (Figure 3).

Humanizing Antibodies
PoET-2 can also be used for antibody humanization, whereby an antibody from a non-human organism such as mouse is redesigned to appear human-derived. To do so, we can task PoET-2 with redesigning only the framework regions of the antibody while preserving the complementary determining regions (CDRs) that enable the antibody to bind with the desired target. To focus PoET-2 on generating human antibodies rather than antibodies from another species, we simply prompt PoET-2 with general human antibodies.
Prompt: Generate humanized antibodies:
- Context: diverse, naive human antibody variable regions from repertoire sequencing representing the distribution of human antibody sequences.
- Query: input antibody variable region with framework region masked and CDRs constrained.
Output: PoET-2 generates antibody variable region sequences matching the input CDRs and completing the framework region with the most compatible human-like sequence.
Breaking Scaling Laws
While other companies build ever-larger protein language models, PoET-2 achieves superior results with just 182 million parameters through its unique in-context learning and multimodal capabilities, even when operating on sequences alone.
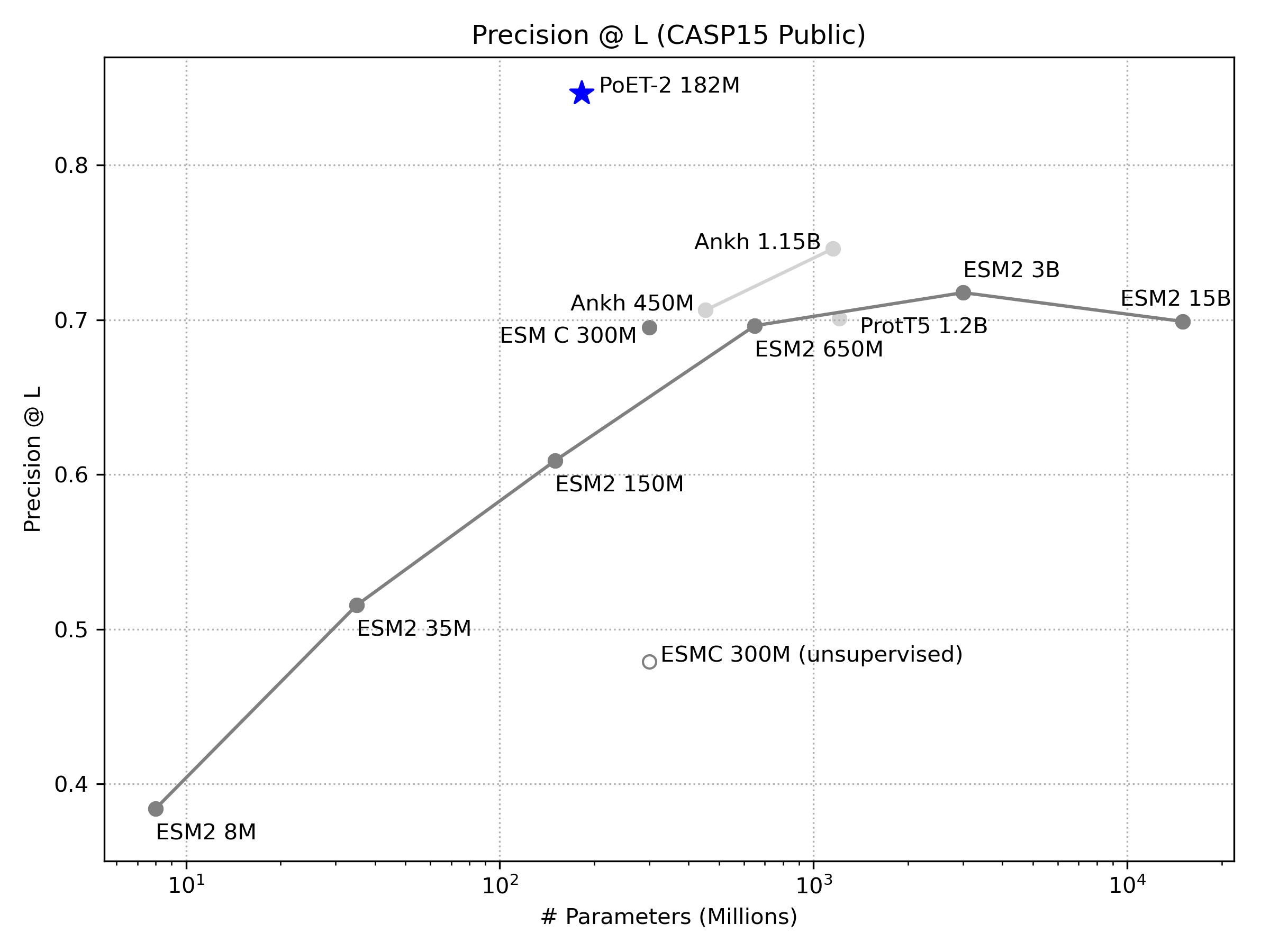
Learning the Language of Proteins
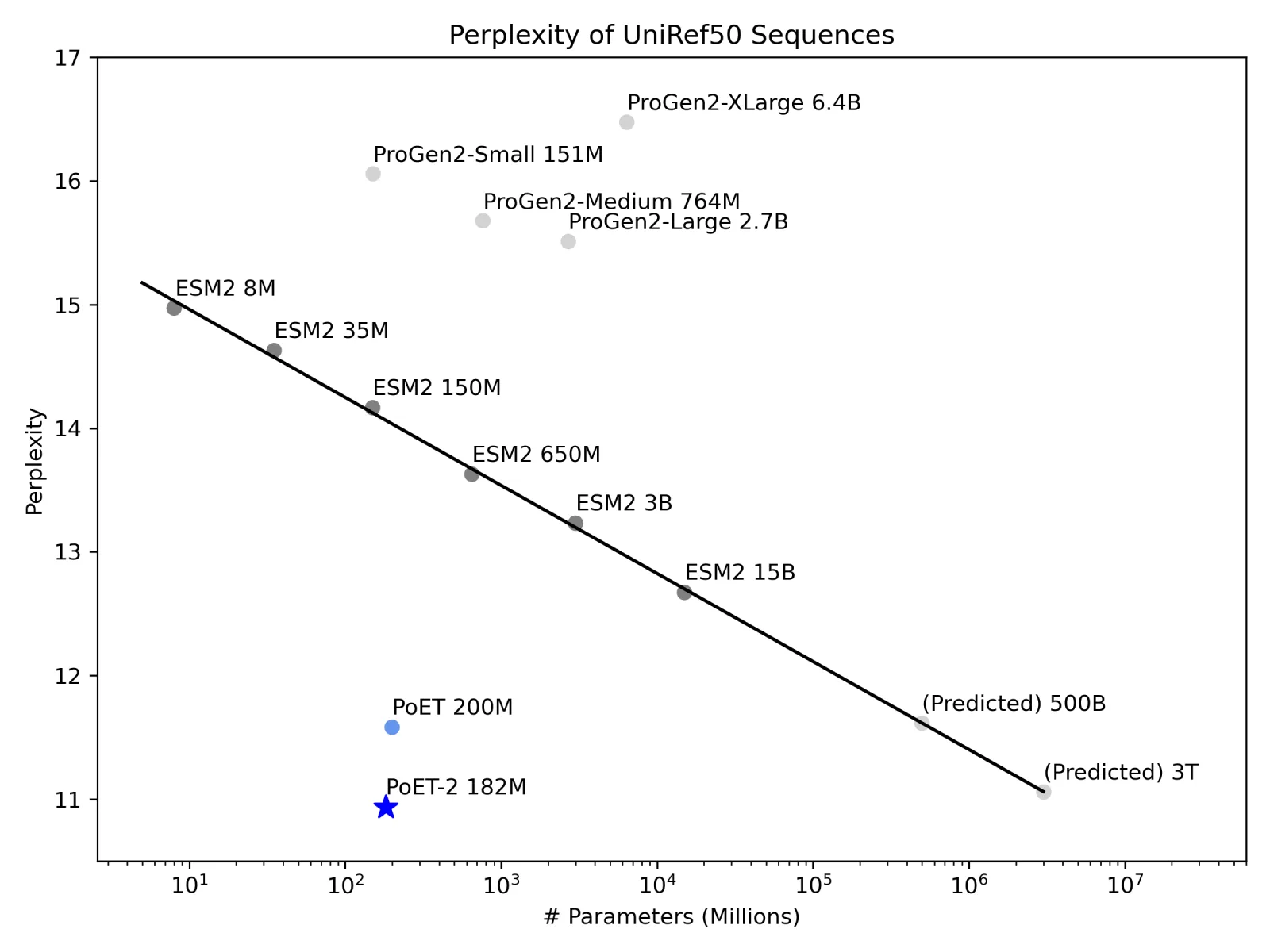
To measure PoET-2's grasp of the rules governing protein sequences, we test its ability to predict missing amino acids from sequence context alone. Lower perplexity indicates a better model of the latent structural and functional constraints on the protein, as inferred from the incompletely observed sequence. We evaluate perplexity on a challenging set of proteins with fewer than 10 detectable evolutionary relatives, where models must understand fundamental principles rather than rely on large scale evolutionary data.
Remarkably, PoET-2 achieves significantly better perplexity than ESM-2 or ProGen2, despite being up to 80x smaller (Figure 4, left). We estimate that a conventional ESM2-like model would need 3 trillion parameters to match PoET-2's performance - significantly larger than any existing PLMs and likely costing hundreds of millions of dollars in compute for training alone.
Discovering Emergent Structure
Although the last generation PoET has impressive representation learning capabilities [2], its unidirectional decoder architecture makes it suboptimal for some tasks where bidirectional context is helpful. We designed PoET-2's bidirectional decoder in part to address these limitations. In order to understand PoET-2's ability to capture distal relationships between residues in protein sequences with this decoder, we examine its supervised contact prediction performance on CASP15 - the gold standard test of structure prediction.
PoET-2 achieves over 80% precision in predicting all protein contacts, surpassing both ESM-2 and the recent ESM-C by more than 10% (Figure 4, right). PoET-2 breaks significantly beyond current scaling laws where large models demonstrate diminishing returns for fully supervised contact prediction [3, 4]. This exceptional performance demonstrates that PoET-2's internal representations directly capture long-range physical relationships between amino acids. This suggests that sequence representations derived from PoET-2 can be leveraged for function prediction with remarkable epistatic awareness - a phenomena which we'll demonstrate later.
PoET-2 delivers trillion-parameter model performance with 500x less compute than contemporary models. This translates into improved sequence and structure understanding with faster inference and lower deployment costs.
Zero-shot Variant Effect Prediction for Substitutions, Insertions, and Deletions
Zero-shot variant effect prediction refers to the task of predicting the effect of mutations on function without training on any experimental training data. It reveals how well protein language models have learned the underlying principles that determine protein function. Strong performance suggests a model has discovered fundamental rules about sequence-function relationships, evolutionary constraints, physical principles relating to how amino acids interact to maintain structure and function, and how mutations work together in the case of higher-order effects. This task also has practical utility for in silico protein library design - better performance means better performing variants in libraries.
PoET-2 is a powerful zero-shot variant effect predictor, improving our ability to understand the impact of mutations on protein function and fitness. Like other protein language models, PoET-2 assigns each protein a score, called the likelihood, that predicts the overall fitness of the protein. But unlike most other models, PoET-2's fully generative architecture allows it to assess not only substitutions, but also insertions and deletions (indels), greatly expanding the mutational landscape that can be interrogated via zero-shot prediction.
We evaluate PoET-2's zero-shot prediction performance by measuring how well the likelihood correlates with experimental measurements of protein function and fitness, such as activity, expression, and stability. When benchmarked on ProteinGym, a comprehensive collection of more than 200 experimental datasets spanning a wide variety of protein functions and taxonomies, we find that PoET-2 clearly separates from other PLMs for predicting the effect of substitutions (Table 1, top). PoET-2 beats the ESM model series and ProGen2 by a large margin across use cases, improving by almost 50% on the hardest proteins. PoET-2 dramatically outperforms the contemporary and much larger ESM-3, which performs slightly worse than ESM-2 on variant effect prediction [5]. Compared with other multimodal models, PoET-2 also performs best on the most challenging tasks: shallow MSAs and combinatorial variants. In addition, PoET-2 is the only multimodal model capable of making predictions on indels, and sets a new standard for zero-shot indel effect prediction.
Substitutions by MSA Depth
| Substitutions by MSA Depth | |||||||
|---|---|---|---|---|---|---|---|
| Model | Multimodal | Retrieval Augmented | Low | Medium | High | All | Indels |
| PoET-2 + ProSST | ✓ | ✓ | 0.529 | 0.549 | 0.594 | 0.542 | N/A |
| PoET-2 | ✓ | ✓ | 0.494 | 0.504 | 0.557 | 0.5 | 0.541 |
| SaProt | ✓ | ✗ | 0.398 | 0.451 | 0.545 | 0.458 | N/A |
| ProSST | ✓ | ✗ | 0.475 | 0.51 | 0.576 | 0.508 | N/A |
| PoET | ✗ | ✓ | 0.489 | 0.472 | 0.514 | 0.47 | 0.517 |
| ESM-1b | ✗ | ✗ | 0.352 | 0.399 | 0.481 | 0.395 | N/A |
| ESM-1v | ✗ | ✗ | 0.328 | 0.406 | 0.499 | 0.407 | N/A |
| ESM-2 | ✗ | ✗ | 0.336 | 0.407 | 0.516 | 0.415 | N/A |
| ProGen2 | ✗ | ✗ | 0.352 | 0.404 | 0.444 | 0.39 | 0.43 |
| MSA Transformer | ✗ | ✓ | 0.402 | 0.45 | 0.481 | 0.431 | N/A |
| TranceptEVE | ✗ | ✓ | 0.45 | 0.468 | 0.492 | 0.456 | 0.414 |
| GEMME | ✗ | ✓ | 0.453 | 0.471 | 0.497 | 0.455 | N/A |
| Substitutions by Mutation Depth | |||||
|---|---|---|---|---|---|
| Model | 1 | 2 | 3 | 4 | 5+ |
| PoET-2 + ProSST | 0.556 | 0.403 | 0.442 | 0.394 | 0.435 |
| PoET-2 | 0.508 | 0.354 | 0.441 | 0.402 | 0.447 |
| ProSST | 0.522 | 0.39 | 0.321 | 0.274 | 0.334 |
| ESM-2 | 0.421 | 0.244 | 0.218 | 0.159 | 0.22 |
| ProGen2 | 0.385 | 0.18 | 0.276 | 0.214 | 0.283 |
PoET-2 performs remarkably well at predicting epistatic effects - how multiple mutations interact to produce protein function (Table 1, bottom). Simple models treat mutations independently, while large PLMs are susceptible to memorizing variants from protein databases. PoET-2 outperforming larger models on higher-order mutations suggests it has developed richer internal representations of protein structure and function, capturing complex statistical couplings between residues. We also find that ensembling PoET-2 with other models can yield further improvements in variant effect prediction, which could mean that these models have discovered orthogonal patterns that could be integrated into future PoET iterations.
PoET-2's sequence likelihoods correlate strongly with protein properties like binding affinity, enzyme activity, and thermostability - all features that evolution selects for - allowing protein engineers to design functional proteins without any experimental data. However, likelihoods provide only relative predictions of these properties, much like mileage driven predicts but doesn't directly measure fuel consumed. This is the fundamental limitation of zero-shot predictions. Through transfer learning, PoET-2's deep understanding of protein biology can be calibrated with experimental data to directly predict specific properties. These specialized models achieve unprecedented accuracy while requiring minimal measurements.
Protein Property Prediction for Iterative Protein Design
Protein property predictors serve as essential tools in protein engineering by transforming experimental data into actionable insights about novel protein variants. Trained on datasets of known protein sequences and their measured properties—such as stability, binding affinity, or catalytic activity—these models can then be used to predict these properties for new, untested variants. By identifying variants likely to exhibit desired characteristics, predictors guide researchers towards promising candidates for experimental validation. This creates a powerful iterative cycle where predictions inform experimental design, and experimental results refine future predictions, accelerating the protein optimization process.
Collecting assay measurements is expensive and slow. Hence it is imperative that models achieve the best performance with the smallest amount of data. Our extensive testing demonstrates that PoET-2's representations enable unprecedented transfer learning capabilities, setting a new standard for data efficiency in protein property prediction. Its sophisticated internal representations of protein biology provide a foundation for building specialized models that accurately predict any measurable protein property. Specifically, models built with PoET-2 require significantly less training data than other models to achieve high accuracy, ultimately reducing both the time and cost of protein engineering while increasing the likelihood of successful optimization.
State-of-the-art Protein Property Prediction
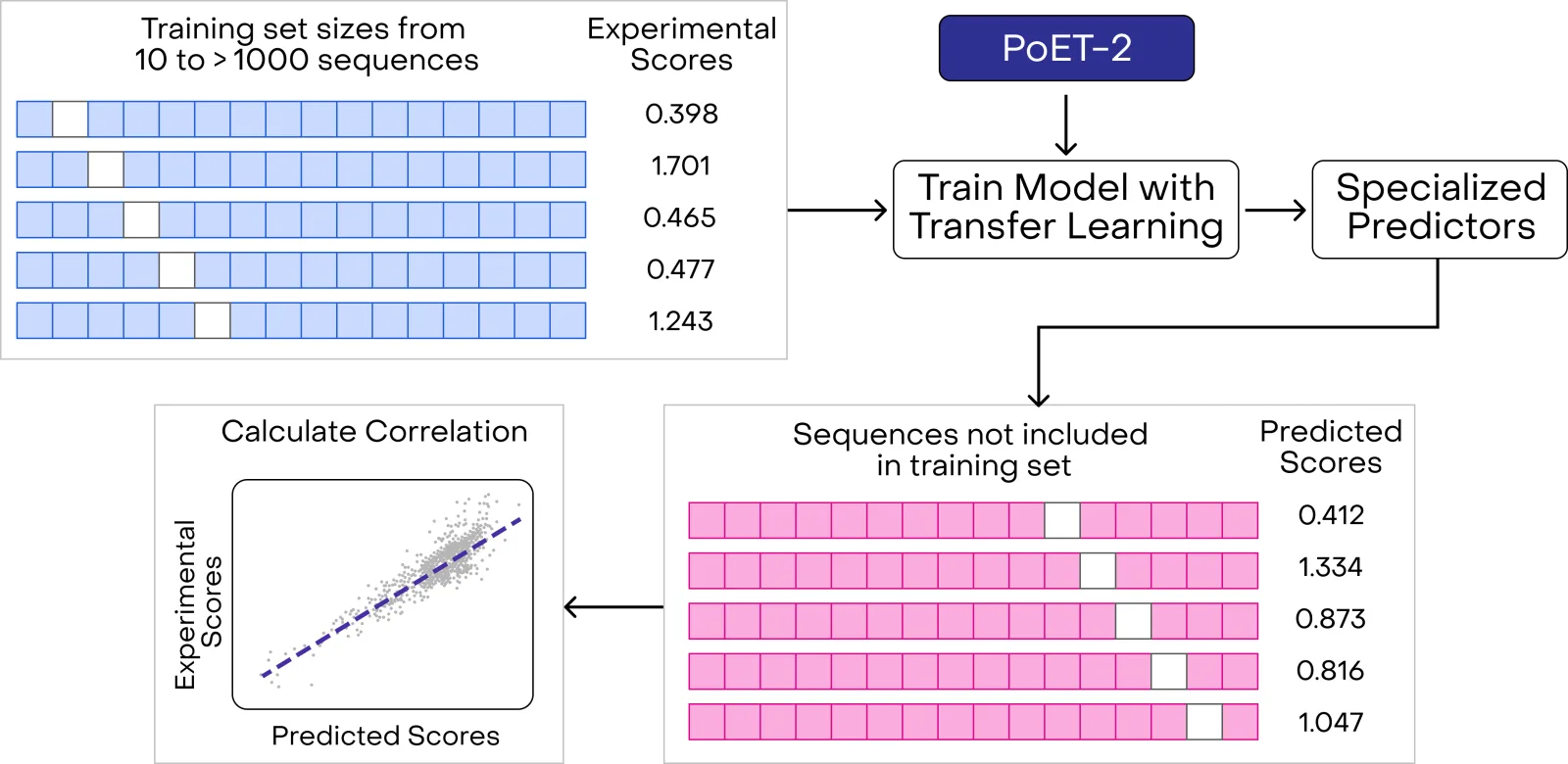
We demonstrate PoET-2's transfer learning capabilities on the supervised ProteinGym benchmark. This uses the same datasets as our zero-shot experiment, but this time allows models to see a limited number of experimental measurements. Each dataset contains thousands of protein variants with experimental measurements of properties like binding affinity, stability, or enzyme activity.
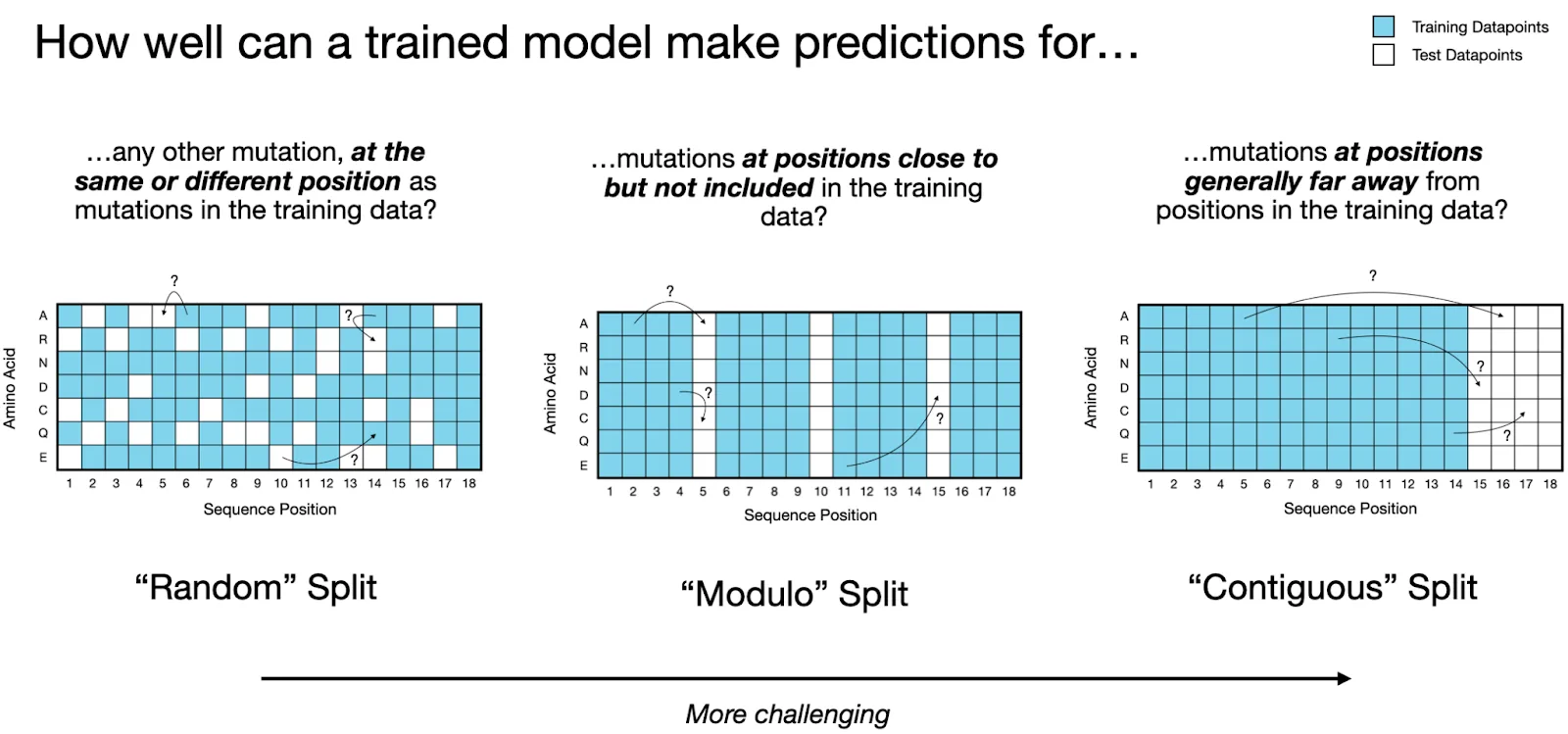
To reflect real-world protein engineering campaigns, we train property prediction models using PoET-2's sequence representations with varying amounts of experimental data, from just 10 measurements to over 1,000. We assess these models' ability to generalize using three increasingly difficult test scenarios (Figure 6):
- Random: Predict new mutations at positions seen in training
- Modulo: Predict mutations at regularly spaced unseen positions
- Contiguous: Predict mutations in entirely unexplored regions
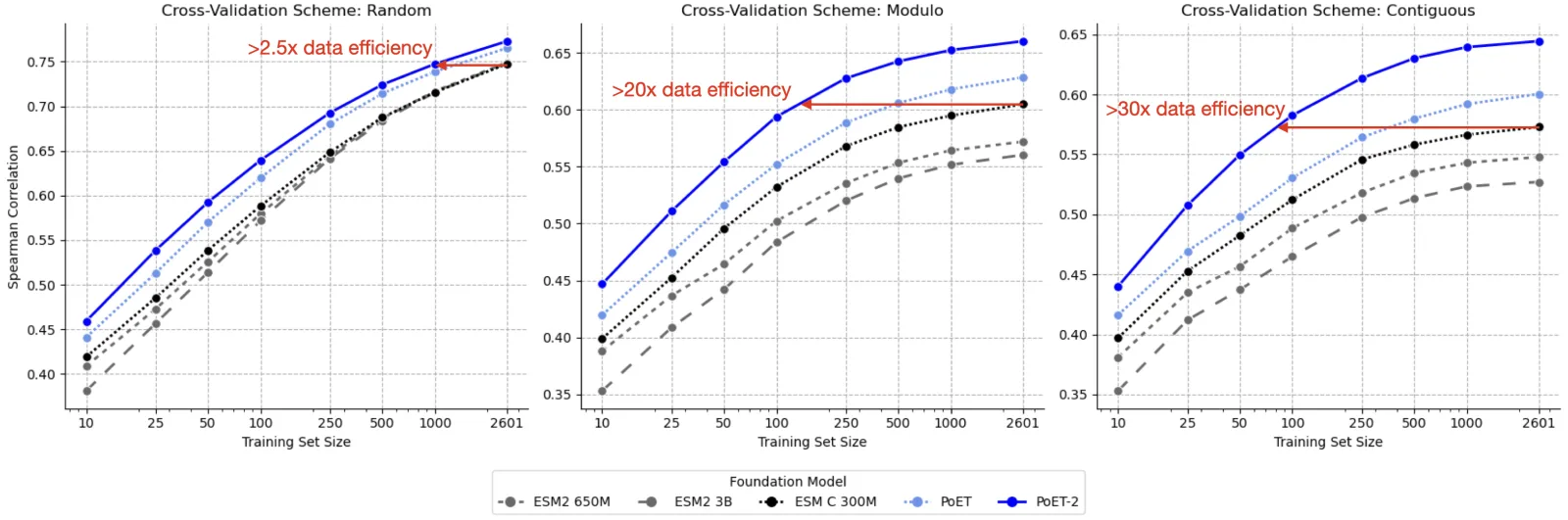
We find that property prediction models built using representations from PoET-2 significantly outperform those that use representations from other models, across all training set sizes and data splits (Figure 7). On the most difficult split, requiring generalization to distant residues within each sequence, PoET-2 requires 30x less data than the next best competitor model to achieve the same performance. In practical terms, PoET-2 reduces the need for experimental data by as much as 30-fold and delivers maximum performance for any data budget. With only dozens of data points, PoET-2-based models outperform ESM2-based models with thousands of datapoints.
Our data titration analysis demonstrates PoET-2's broad applicability to any protein and any property - from transcriptional activity and stability to expression, binding, and enzyme function. Using ProteinGym's diverse dataset, we show that PoET-2 achieves exceptional performance with minimal training data, delivering both high correlation on held-out test sets and accurate prediction of top variants across diverse protein modalities (Figure 8).
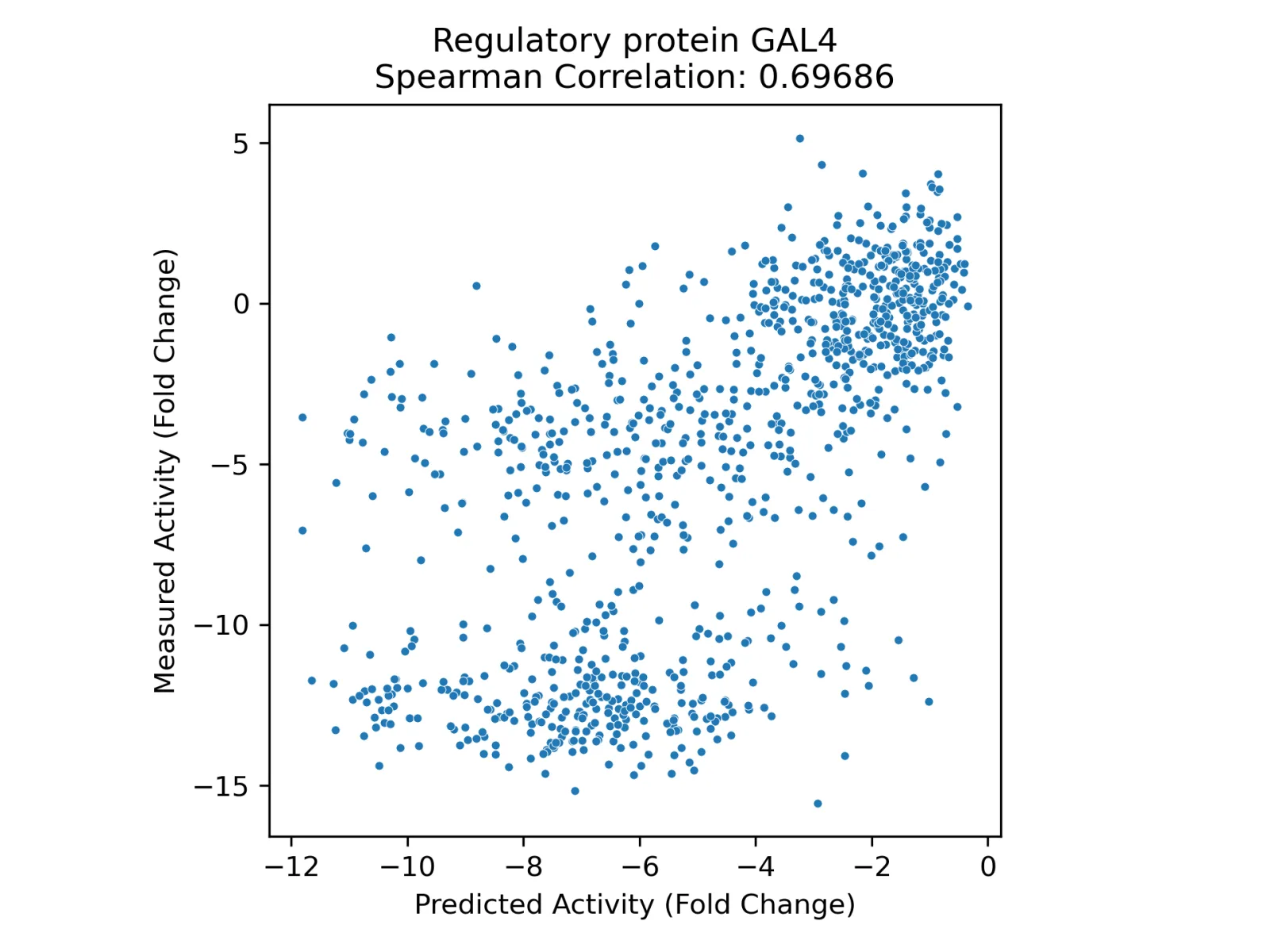
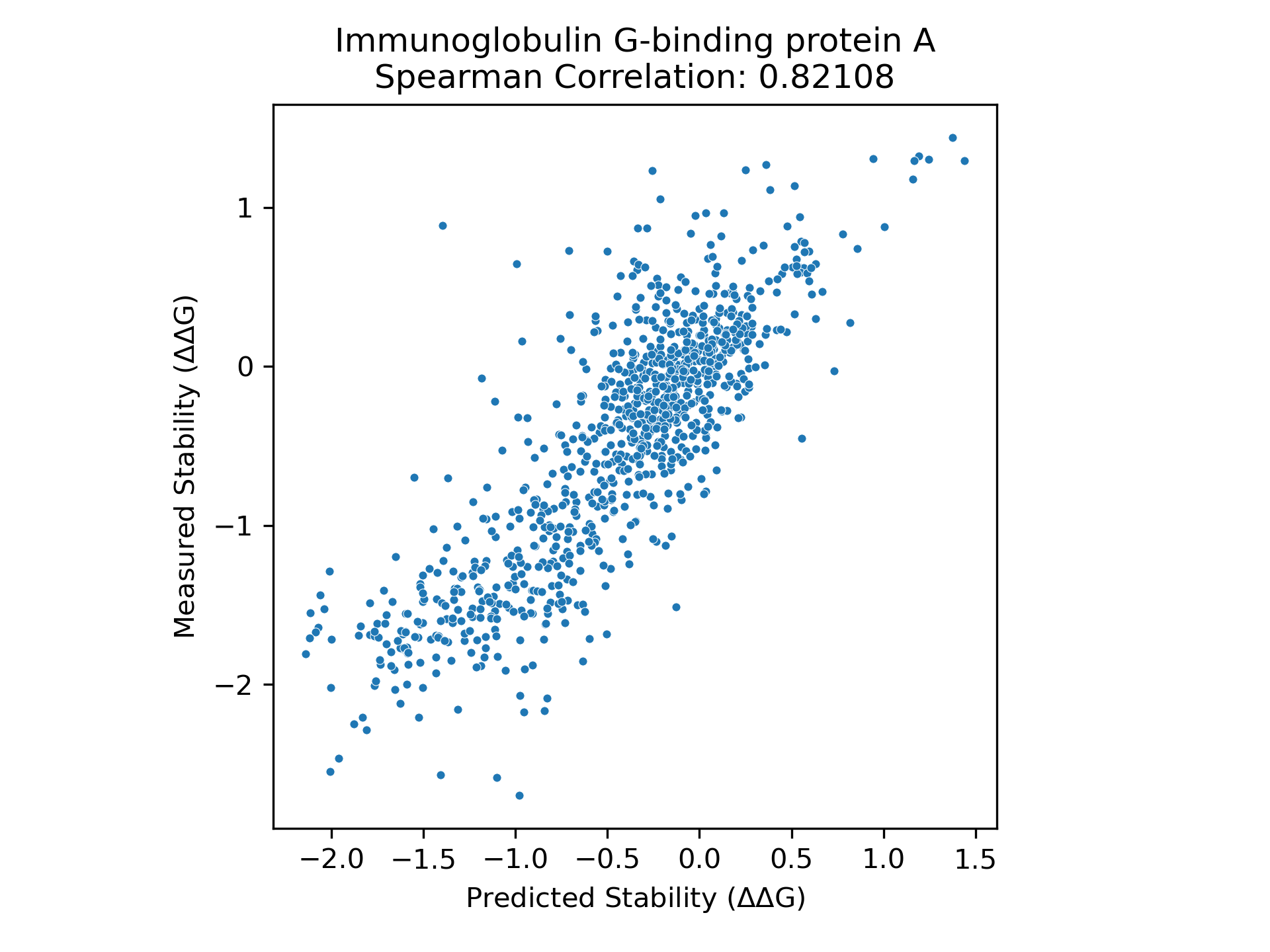
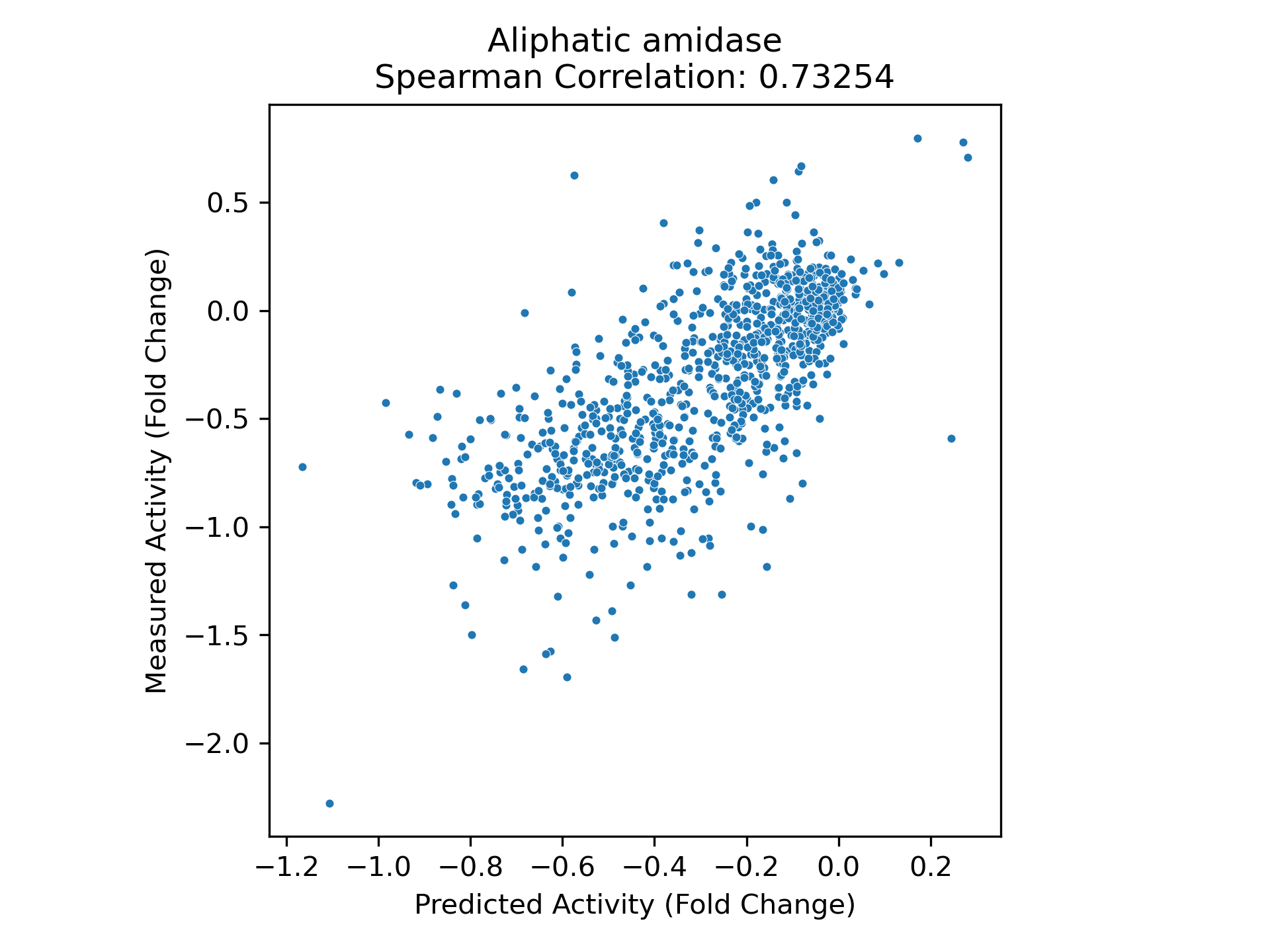
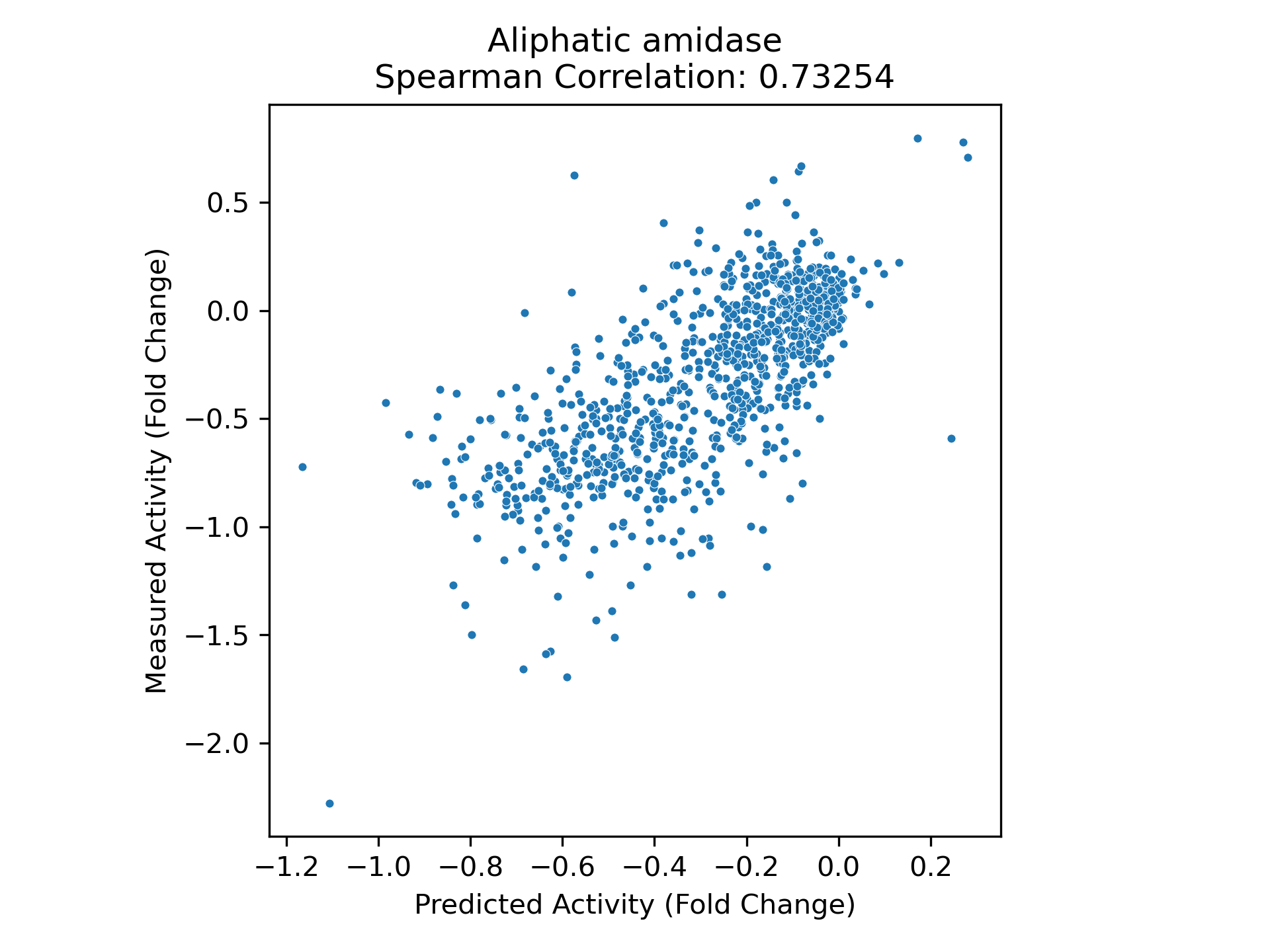
This systematic evaluation reveals both PoET-2's fundamental understanding of protein properties and its practical value for protein engineering. Strong performance with minimal data demonstrates that PoET-2's representations capture meaningful protein features. Performance on unseen positions shows it understands distal relationships beyond simple pattern matching.
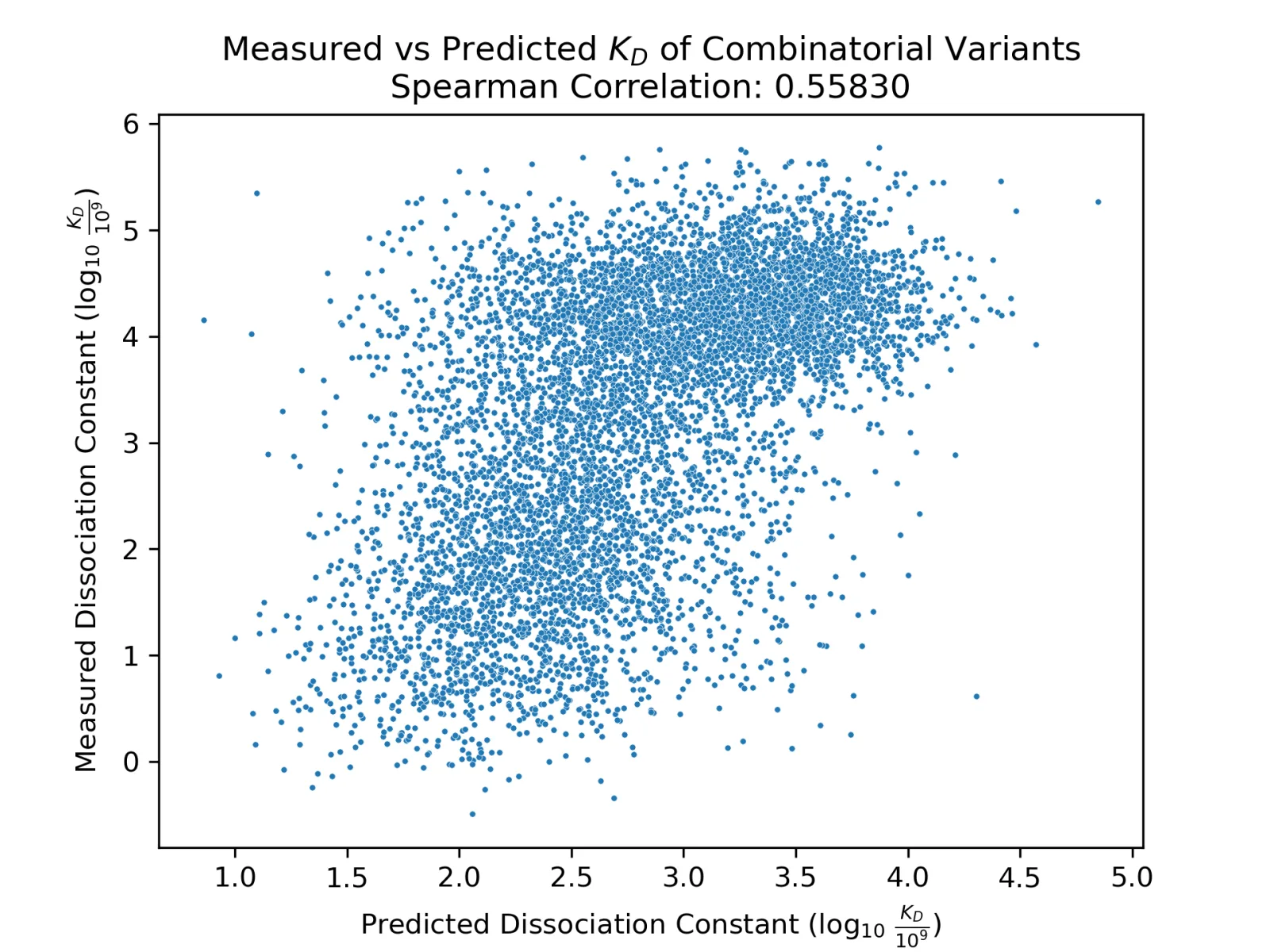
Mapping Combinatorial Variants to Design Sub-nanomolar Affinity Antibodies
PoET-2's exceptional data efficiency in property prediction makes it particularly powerful for navigating the vast space of combinatorial protein variants. By learning from single mutants to predict combinatorial variant function, PoET-2 based predictors identify large steps in mutation space that confer enhanced function. This is crucial for optimizing success rates with minimal data and reducing design-build-test cycles.
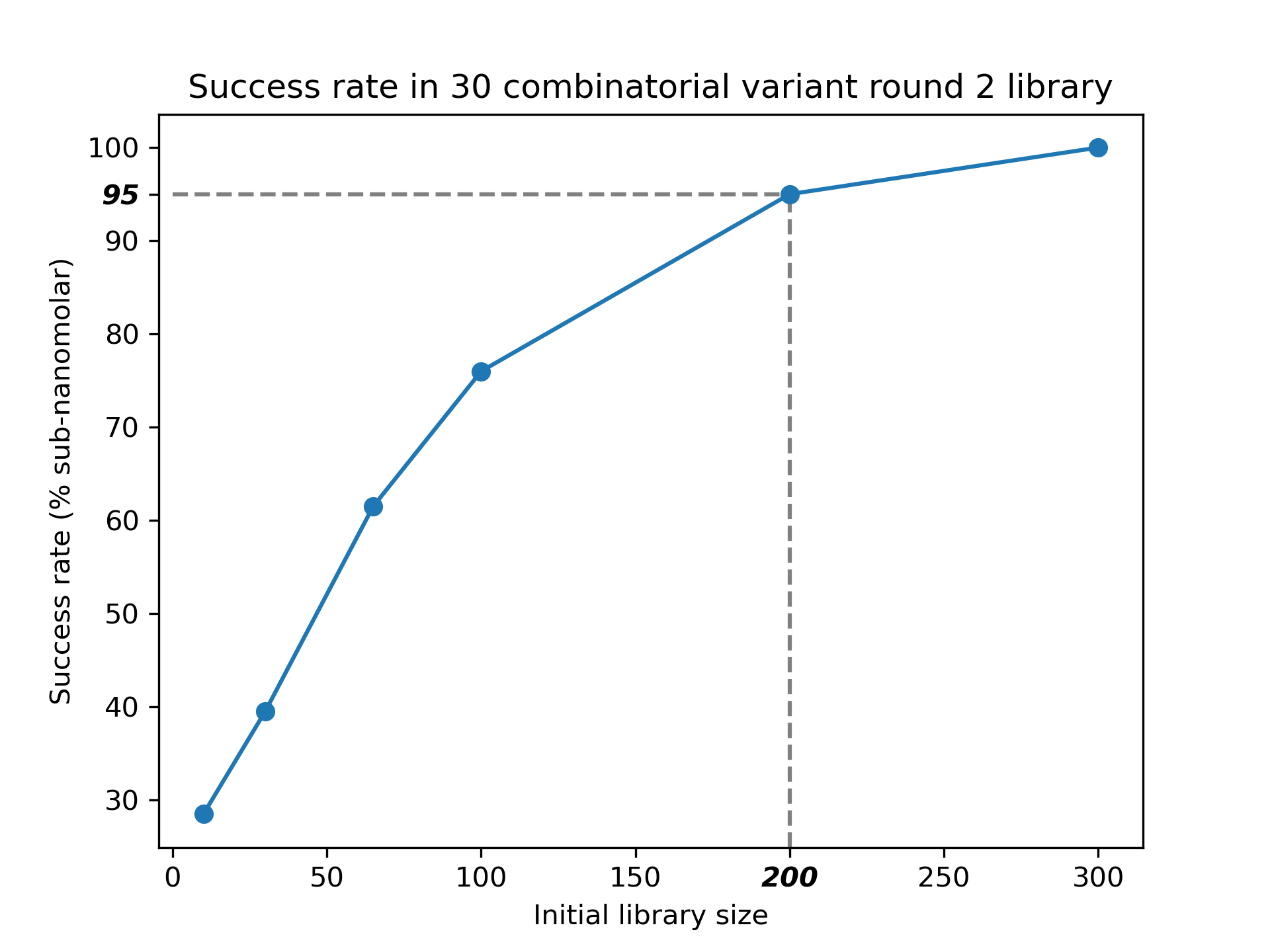
In a case study optimizing an antibody targeting the HR2 region of the coronavirus spike protein [6], we demonstrate that a PoET-2 based predictor trained only on single mutations accurately identifies combinatorial variants with sub-nanomolar binding affinities. This is an immensely challenging task because the space of combinatorial mutants is exponentially large: given 30 sites, there are ~500 possible single mutations, but >25,000,000 double and triple mutants. Of these, only 0.1% are subnanomolar binders. Here, we consider the problem of designing a combinatorial variant library containing only 30 sequences after observing an initial round of single mutants.
After observing an initial round of only 30 single mutants, PoET-2 designs combinatorial variant libraries with a >40% chance of success (as defined by containing a sub-nanomolar binder), an astounding >100x improvement over random chance. At 200 single mutants, PoET-2 reaches a 97% chance of success.
PoET-2's ability to understand these epistatic effects translates directly to real world protein engineering challenges, dramatically reducing experimental overhead.
Simultaneous Optimization of Multiple Properties
Industrial applications often require optimizing multiple protein properties simultaneously, such as enhancing both enzymatic activity and thermostability. PoET-2 excels in addressing these complex challenges, thanks to its versatility and applicability across diverse protein properties, making it a powerful tool for intelligent multi-property optimization.
Here, we use PoET-2 to optimize the activity and thermostability of alpha-amylase (α-amylase), a critical industrial enzyme that catalyzes the breakdown of starch and glycogen into smaller sugars (Figure 10). In the first round of optimization, PoET-2's zero-shot design capability generates a 50-variant single-site mutation library. Even without training data, this approach identifies variants with more than a two-fold improvement over the parent sequence in both activity and thermostability.
Building on this success, subsequent rounds leverage supervised learning to integrate data from earlier rounds. In each iteration, PoET-2 carefully balances exploration and exploitation when selecting the next round's 50-variant library: exploration ensures diverse, informative data for learning sequence-property relationships, while exploitation focuses on promising regions of sequence space for immediate gains. This strategic approach results in substantial improvements over two additional rounds, where PoET-2 identifies variants with a more than 10-fold increase in enzymatic activity and a more than 45-fold increase in thermostability. PoET-2 navigates the complex multi-property fitness landscape efficiently, even with a modest library size of just 50 variants per round.
Towards AI that Understands the Machines of Life
The ability to understand and engineer proteins - nature's molecular machines - has long been one of biology's greatest challenges. PoET-2 represents a significant step toward artificial intelligence that can truly comprehend the language of life, not just through brute-force computation, but by learning nature's own design principles. By combining insights from evolution, structure, and function, PoET-2 begins to mirror how nature itself explores and optimizes the vast space of possible proteins.
Yet we are still in the early stages of this journey. Many capabilities remain to be developed: systems for de novo binder design, modeling of protein-protein and protein-ligand interactions, precise control over properties like solubility and cellular localization, and integration across DNA, RNA, and protein. These challenges represent some of the next frontiers we hope to explore with PoET-2 and future models.
At OpenProtein.AI, we will continue to develop AI systems that can better understand and work with the fundamental building blocks of life, and to make these tools available to the wider community. From more effective medicines to novel enzymes that could help address climate change, the ability to understand and engineer proteins with precision opens possibilities we are only beginning to explore.
How Can You Access PoET-2?
PoET-2 is now available as a generative model for zero-shot variant effect prediction and as a foundation model for training sequence-to-property models in the OpenProtein.AI web app. Embeddings and other low level outputs from the model are available via our Python Client and APIs. The OpenProtein.AI web platform is completely free for academic use.
Additional features to expose the full generative power of PoET-2 will be coming soon to our web app and APIs.
What's Coming Next?
We will be releasing a pre-print with full model and experimental details as well as code and model parameters under a non-commercial use license in the near future. Open science is critical to our mission at OpenProtein.AI and we are committed to responsibly releasing our models to the community.
How to Cite PoET-2?
Our upcoming pre-print will be the best way to cite PoET-2, and we will update this section with the relevant citation once it is available. In the meantime, please cite:
References
[1] Truong, T. F., Jr., & Bepler, T. (2023). PoET: A generative model of protein families as sequences-of-sequences. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, & S. Levine (Eds.), Advances in Neural Information Processing Systems (Vol. 36, pp. 77379–77415). Curran Associates, Inc. [https://proceedings.neurips.cc/paper_files/paper/2023/file/f4366126eba252699b280e8f93c0ab2f-Paper-Conference.pdf]
[2] Truong, T. F., Jr., & Bepler, T. PoET: A Foundation Model for High Accuracy Protein Property Prediction. (2024). OpenProtein.AI. [https://www.openprotein.ai/poet-foundation-model-for-high-accuracy-protein-property-prediction]
[3] Chen, B., Cheng, X., Li, P., Geng, Y., Gong, J., Li, S., Bei, Z., Tan, X., Wang, B., Zeng, X., Liu, C., Zeng, A., Dong, Y., Tang, J., & Song, L. (2024). xTrimoPGLM: Unified 100B-Scale Pre-trained Transformer for Deciphering the Language of Protein (No. arXiv:2401.06199). arXiv. [https://doi.org/10.48550/arXiv.2401.06199]
[4] Elnaggar, A., Essam, H., Salah-Eldin, W., Moustafa, W., Elkerdawy, M., Rochereau, C., & Rost, B. (2023). Ankh: Optimized Protein Language Model Unlocks General-Purpose Modelling (No. arXiv:2301.06568). arXiv. [https://doi.org/10.48550/arXiv.2301.06568]
[5] Hayes, T., Rao, R., Akin, H., Sofroniew, N. J., Oktay, D., Lin, Z., Verkuil, R., Tran, V. Q., Deaton, J., Wiggert, M., Badkundri, R., Shafkat, I., Gong, J., Derry, A., Molina, R. S., Thomas, N., Khan, Y. A., Mishra, C., Kim, C., ... Rives, A. (2025). Simulating 500 million years of evolution with a language model. Science, 0(0), eads0018. [https://doi.org/10.1126/science.ads0018]
[6] Li, L., Gupta, E., Spaeth, J., Shing, L., Jaimes, R., Engelhart, E., Lopez, R., Caceres, R. S., Bepler, T., & Walsh, M. E. (2023). Machine learning optimization of candidate antibody yields highly diverse sub-nanomolar affinity antibody libraries. Nature Communications, 14(1), 3454. [https://doi.org/10.1038/s41467-023-39022-2]
[7] van der Flier, F., Estell, D., Pricelius, S., Dankmeyer, L., van Stigt Thans, S., Mulder, H., Otsuka, R., Goedegebuur, F., Lammerts, L., Staphorst, D., van Dijk, A. D. J., de Ridder, D., & Redestig, H. (2024). Enzyme structure correlates with variant effect predictability. Computational and Structural Biotechnology Journal, 23, 3489–3497. [https://doi.org/10.1016/j.csbj.2024.09.007]